
Meta's Petabyte-Scale Data Ingestion Overhaul

Alps Wang
May 30, 2026 · 1 views
Petabyte-Scale Reliability Achieved
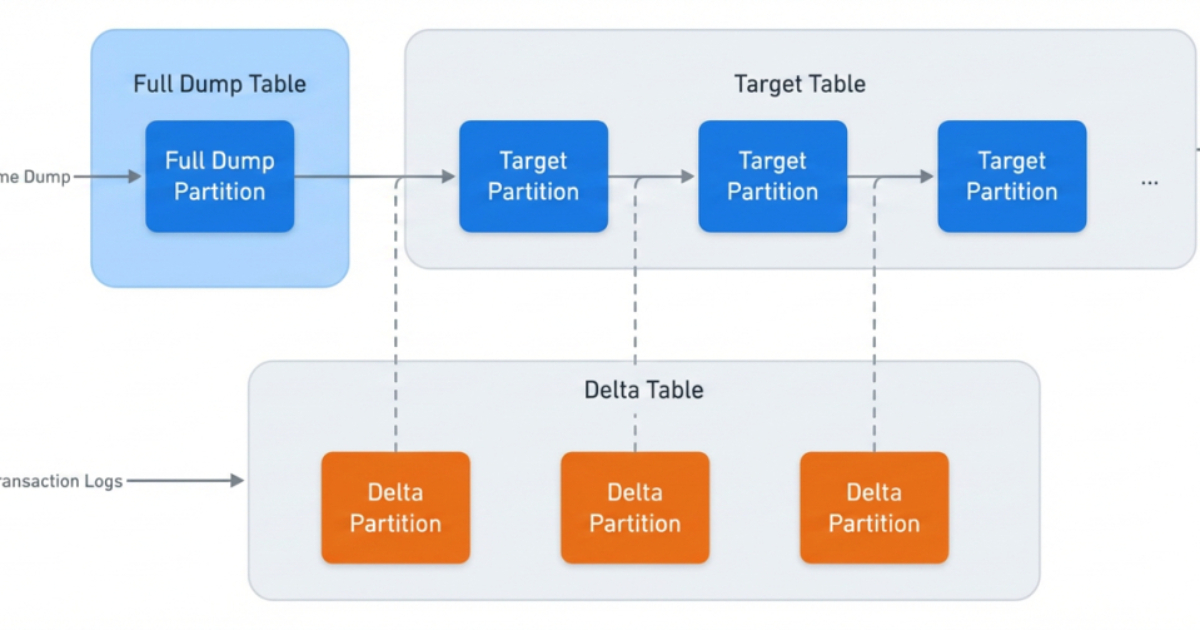
Meta's approach to rebuilding its petabyte-scale data ingestion platform highlights a sophisticated, multi-stage migration strategy that prioritizes reliability and operational efficiency. The use of reverse shadowing and continuous checksum monitoring are particularly noteworthy techniques for ensuring data integrity and zero downtime during such a massive undertaking. By replacing fragmented, pipeline-owned infrastructure with a centralized, self-managed warehouse service, Meta has undoubtedly gained significant advantages in terms of manageability and resource optimization. The staged rollout, including shadow, reverse shadow, and cleanup phases, demonstrates a robust, risk-averse methodology crucial for systems of this magnitude. Furthermore, the emphasis on automated validation, rollback controls, and compatibility layers showcases a mature DevOps culture focused on minimizing disruption. The article effectively communicates the complexity and meticulous planning required for such a migration, making it a valuable case study for organizations grappling with large-scale data infrastructure challenges. The reliance on Change Data Capture (CDC) for incremental updates and the strategic minimization of expensive full snapshots during migration are also key takeaways for optimizing performance and resource utilization.
However, while the article paints a picture of success, several aspects warrant deeper consideration. The 'centralized, self-managed warehouse service' sounds like a significant internal platform development. The article doesn't delve deeply into the specifics of this new service's architecture, its underlying technologies, or the operational overhead associated with managing it at Meta's scale. The cost implications of such a centralized system versus a distributed, customer-owned pipeline model, even with fragmentation, are not fully explored. Additionally, while zero downtime is claimed, the article mentions investigating root causes for mismatches and deploying fixes. The extent and impact of these issues on downstream systems, even if transient, could be elaborated upon. The success hinges on the effectiveness of their compatibility layers; understanding the complexity and maintenance burden of these layers would provide further insight. For organizations looking to replicate this, the significant engineering investment and specialized expertise required for building and operating such a custom, centralized platform are substantial barriers. The article is excellent for showcasing what's possible, but a more detailed discussion on the trade-offs, ongoing maintenance, and specific technological choices within the new warehouse service would enhance its practical applicability and critical evaluation. The article could also benefit from more quantitative data on performance improvements, cost savings, or reduction in operational incidents post-migration.
Key Points
- Meta migrated its petabyte-scale MySQL social graph data ingestion platform to a centralized, self-managed warehouse service.
- The migration employed a three-stage approach: shadow, reverse shadow, and cleanup phases.
- Key reliability techniques included continuous checksum monitoring and reverse shadowing to ensure zero downtime.
- The new system replaced fragmented, pipeline-owned infrastructure with a unified, managed system.
- Change Data Capture (CDC) was utilized for incremental data ingestion, with strategic minimization of full dumps during migration.
- Automated validation, rollback controls, and compatibility layers were crucial for seamless transition of thousands of ingestion pipelines.
📖 Source: How Meta Rebuilt Data Ingestion for Petabyte-Scale Reliability
Related Articles
Comments (0)
No comments yet. Be the first to comment!