
Netflix's High-Throughput Graph Abstraction Revealed

Alps Wang
May 30, 2026 · 1 views
Scaling Graphs for Millions
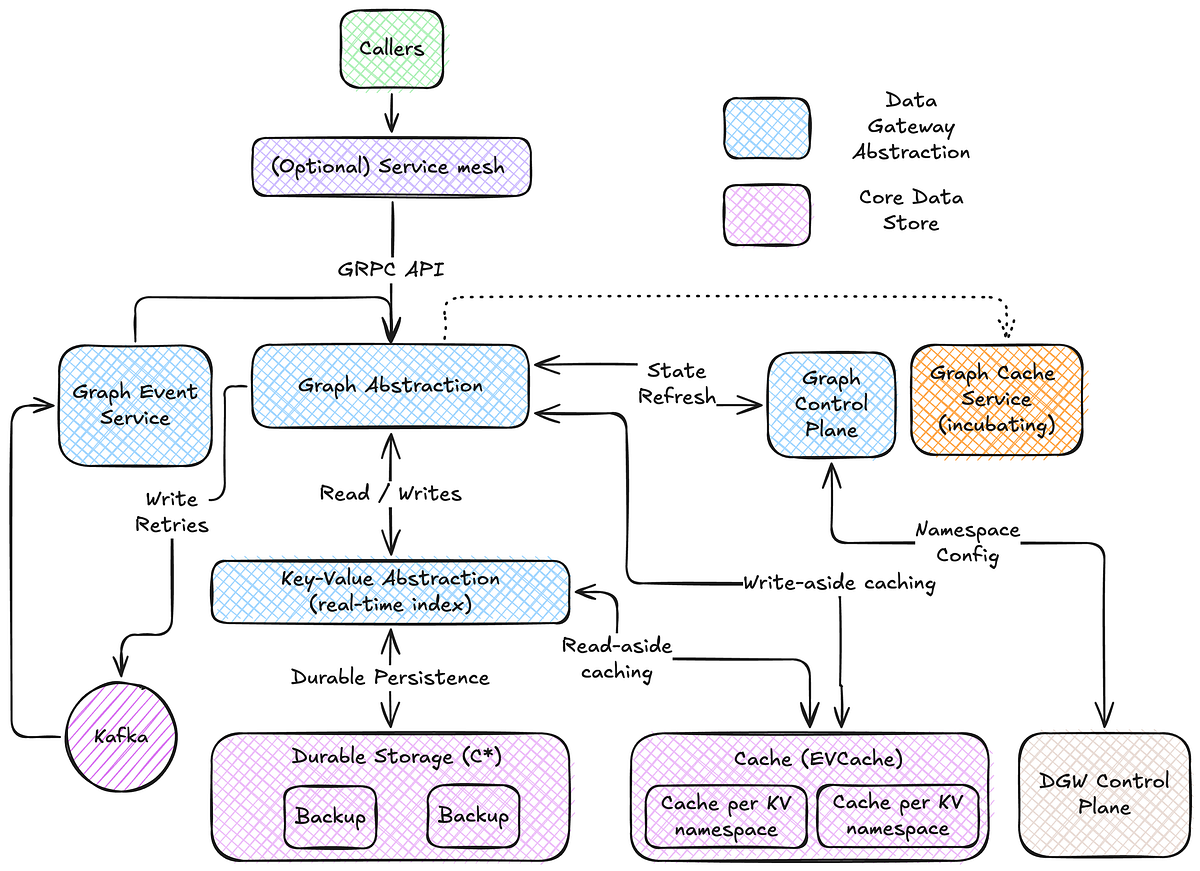
The Netflix Tech Blog's "High-Throughput Graph Abstraction at Netflix: Part I" offers a compelling glimpse into how one of the world's largest streaming services tackles the immense challenge of managing graph data at scale. The article effectively distinguishes between OLAP and OLTP graph workloads, clearly positioning their Graph Abstraction as a solution for the latter, demanding millions of operations per second with millisecond latency. The architectural overview, emphasizing building upon existing Netflix data abstractions like Key-Value (KV) and TimeSeries (TS), highlights a pragmatic approach to leveraging internal infrastructure. The detailed breakdown of the Property Graph model, namespaces, and explicit graph schemas, especially the schema's role in data quality, query planning, and deduplication, is particularly noteworthy. This schema-driven optimization is a sophisticated technique for enhancing performance and developer experience.
However, the article, being Part I, naturally leaves many questions for subsequent installments. While the benefits of separating edge links and properties are explained, the stated trade-off of "non-atomic writes" and the promise of discussing its resolution in "Consistency Enforcement" leaves a critical area for deeper scrutiny. The reliance on eventual consistency for OLTP use cases, while common, always introduces potential complexities for developers integrating with such systems. Furthermore, the mention of limiting the number of edges per source node to manage memory pressure is a practical constraint that could impact certain graph traversal patterns. The discussion on caching strategies, particularly the write-aside for edge links and read-aside for properties, is standard but effective. The development of write-through caching hints at ongoing efforts to further optimize read performance, which will be interesting to follow. Overall, this article lays a strong foundation, demonstrating significant engineering achievement, but the true impact and robustness will be better understood as the series delves into consistency, advanced caching, and query execution.
Key Points
- Netflix has developed a high-throughput graph abstraction specifically for OLTP use cases requiring millions of operations per second with millisecond latency.
- The abstraction builds upon existing Netflix data abstractions like Key-Value (KV) and TimeSeries (TS) for persistence and caching.
- A strongly typed Property Graph model with explicit schemas is used, enabling data quality enforcement, efficient query planning, and traversal optimizations.
- Data is organized into isolated namespaces, and the schema defines node/edge types, properties, and relationships, aiding in query optimization and data validation.
- Real-time indexing uses a two-tiered partitioning strategy in KV for nodes and separates edge links from edge properties for efficiency and wide-row prevention.
- Caching strategies include write-aside for edge links to reduce write amplification and read-aside for properties via EVCache to reduce read amplification.
📖 Source: High-Throughput Graph Abstraction at Netflix: Part I
Related Articles
Comments (0)
No comments yet. Be the first to comment!