
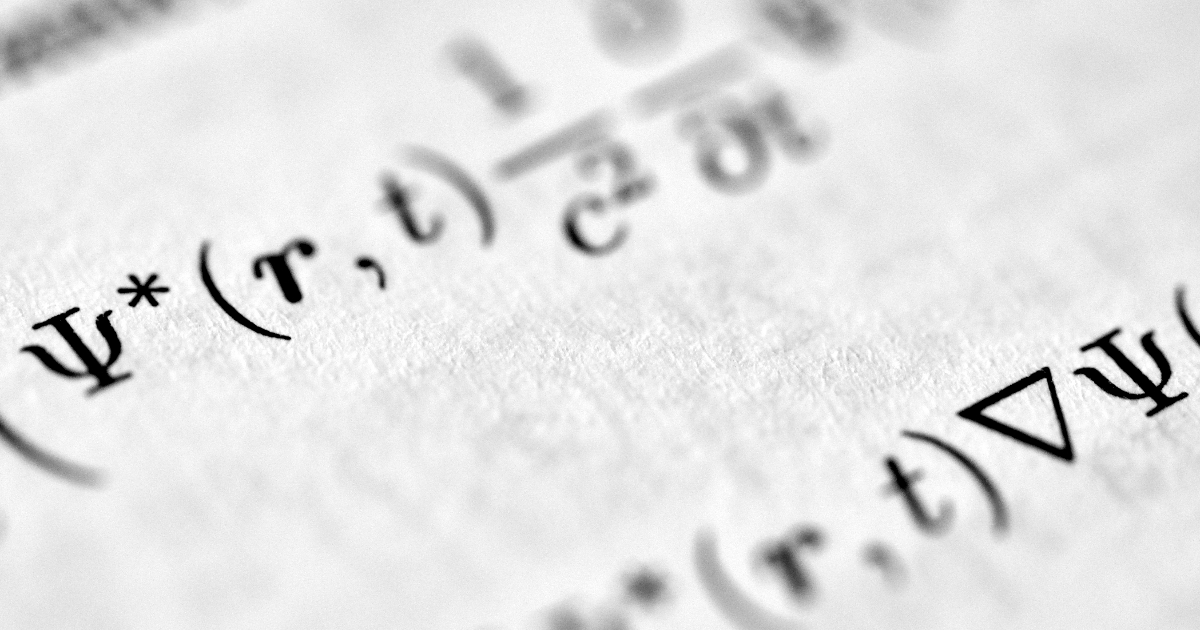
TurboQuant: LLMs Shrink KV Cache, Boost Speed
Unlocking LLM Efficiency with TurboQuant Google Research's TurboQuant presents a compelling solution to a critical challenge in LLM deployment: the prohibitive memory cost of the KV cache, especially...
 Alps Wang
Alps Wang#AI#LLM#Quantization