
Uber's IngestionNext: Streaming Data Lake Slashes Latency, Boosts Efficiency

Alps Wang
Mar 26, 2026 · 1 views
Streaming-First Data Lake Revolution
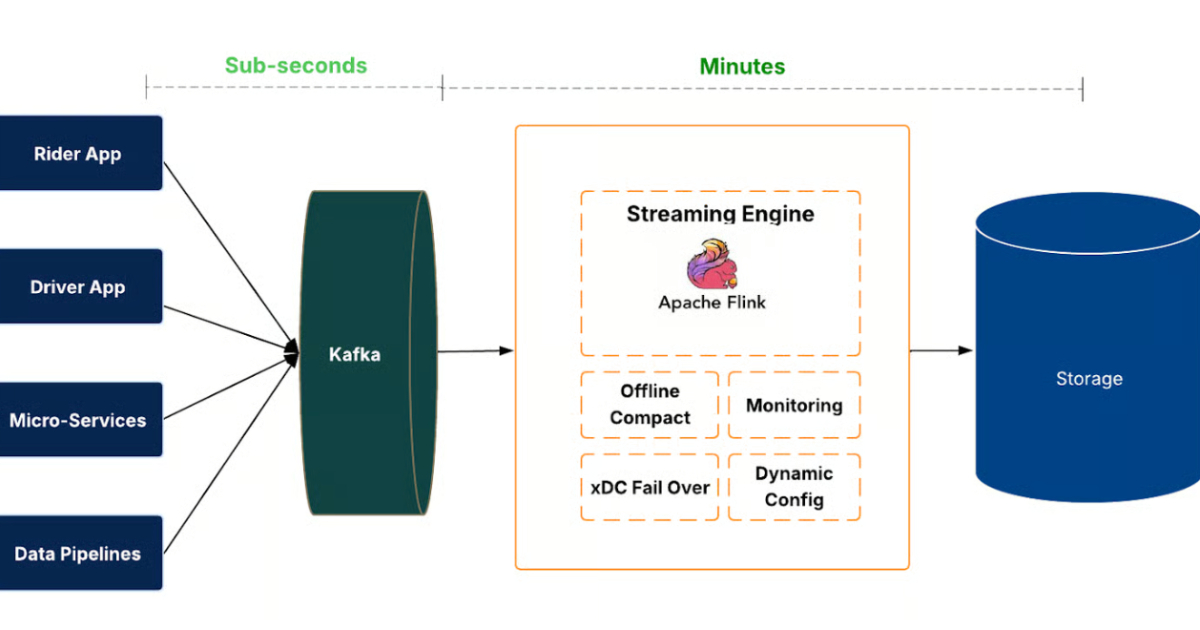
Uber's IngestionNext represents a significant leap forward in data lake architecture, moving from a batch-oriented to a streaming-first paradigm. The reported 25% reduction in latency and compute is a compelling testament to the benefits of this approach, particularly for real-time analytics and ML workloads. By leveraging Apache Kafka for event streaming and Apache Flink for processing, coupled with Apache Hudi for transactional data lake capabilities, Uber is demonstrating a mature and robust solution. The focus on data freshness as a key dimension of data quality, alongside meticulous handling of challenges like small file problems and schema evolution, highlights the depth of engineering involved. This architecture is particularly beneficial for organizations that require low-latency access to fresh data for decision-making and operational intelligence, especially those dealing with high-volume, high-velocity data streams.
However, the article acknowledges that downstream transformations might still introduce latency, indicating that the full end-to-end real-time vision requires further work. The implementation complexity and maintenance overhead associated with advanced features like schema-evolution-aware merging also warrant consideration. While IngestionNext significantly improves raw data ingestion, the overall data pipeline freshness remains dependent on the entire processing chain. For companies considering a similar migration, the investment in specialized skills for streaming technologies, distributed systems, and data lake management will be substantial. The success of IngestionNext also hinges on the continued evolution and stability of its open-source components, particularly Hudi and Flink, which are critical to its transactional and processing guarantees.
Key Points
- Uber has re-architected its data lake ingestion platform to a streaming-first system called IngestionNext.
- This shift reduces ingestion latency from hours to minutes, enabling faster availability for analytics and ML.
- The new platform processes event streams continuously using Apache Kafka and Apache Flink, writing to Apache Hudi tables.
- Key benefits include a 25% reduction in compute usage and improved data freshness.
- Challenges addressed include managing small files in the data lake through merging strategies and compaction.
- The system incorporates robust mechanisms for checkpointing, partition skew, recovery, and automated job management.
- Future work aims to extend streaming capabilities into downstream transformation and analytics pipelines.
📖 Source: Uber Launches IngestionNext: Streaming-First Data Lake Cuts Latency and Compute by 25%
Related Articles
Comments (0)
No comments yet. Be the first to comment!