
Uber's HiveSync: Cross-Region Data Lake Mastery

Alps Wang
Jan 17, 2026 · 1 views
Deconstructing Uber's HiveSync Architecture
Uber's HiveSync presents a compelling solution for cross-region data synchronization and disaster recovery, particularly impressive given the scale – 350PB and millions of events daily. The architecture's core innovation lies in its sharding strategy, DAG-based orchestration, and the separation of control and data planes. This approach allows for parallel replication, fine-grained fault tolerance, and efficient resource utilization, eliminating the need for idle secondary regions. The use of a hybrid strategy leveraging both RPC for small jobs and DistCp on YARN for larger ones demonstrates a pragmatic approach to optimizing performance. The four-hour replication SLA with a 20-minute lag is a strong indicator of the system's robustness, and the Data Reparo service is crucial for maintaining data consistency. However, the article lacks details on the specific hardware infrastructure, network bandwidth, and the cost associated with running such a system. The reliance on MySQL for the control plane, while common, could become a bottleneck at extreme scale, and the article doesn't discuss the scalability of MySQL in this context. Finally, while the article mentions plans for cloud migration, it doesn't elaborate on the challenges of adapting HiveSync to a cloud-native environment with its inherent differences in storage and networking models.
Key Points
- Uber plans to extend HiveSync for cloud replication use cases, leveraging existing architecture for batch analytics and ML pipelines.
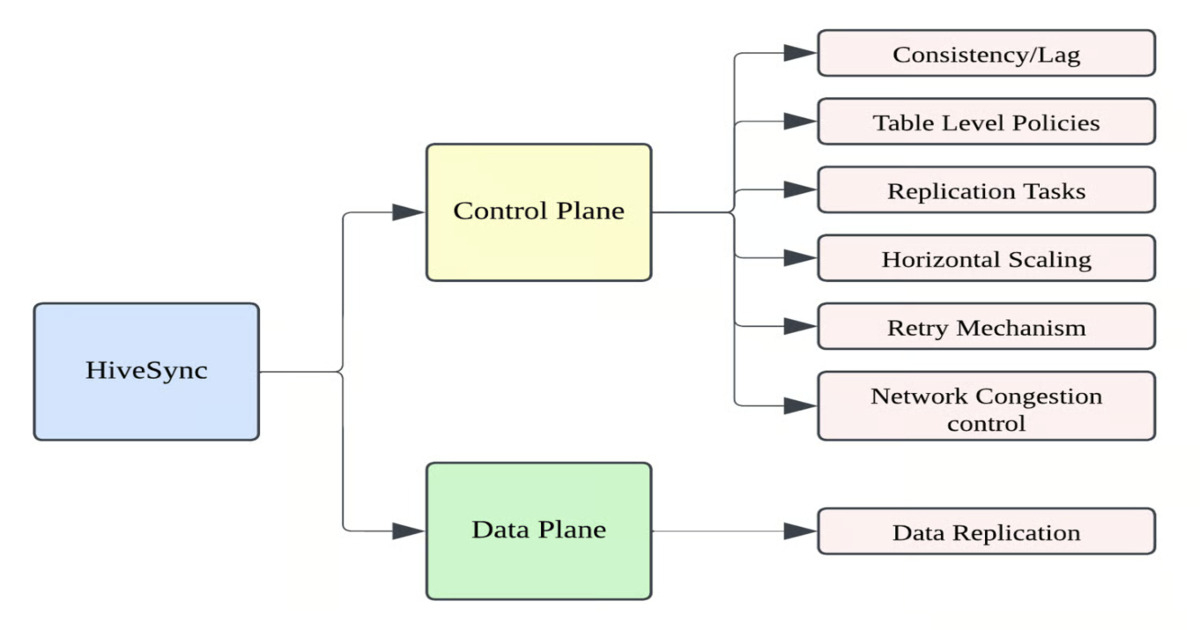
📖 Source: 350PB, Millions of Events, One System: Inside Uber’s Cross-Region Data Lake and Disaster Recovery
Related Articles
Comments (0)
No comments yet. Be the first to comment!