
Netflix's 650TB Graph: Millisecond Global Insights

Alps Wang
Mar 24, 2026 · 1 views
Netflix's Graph Abstraction Unpacked
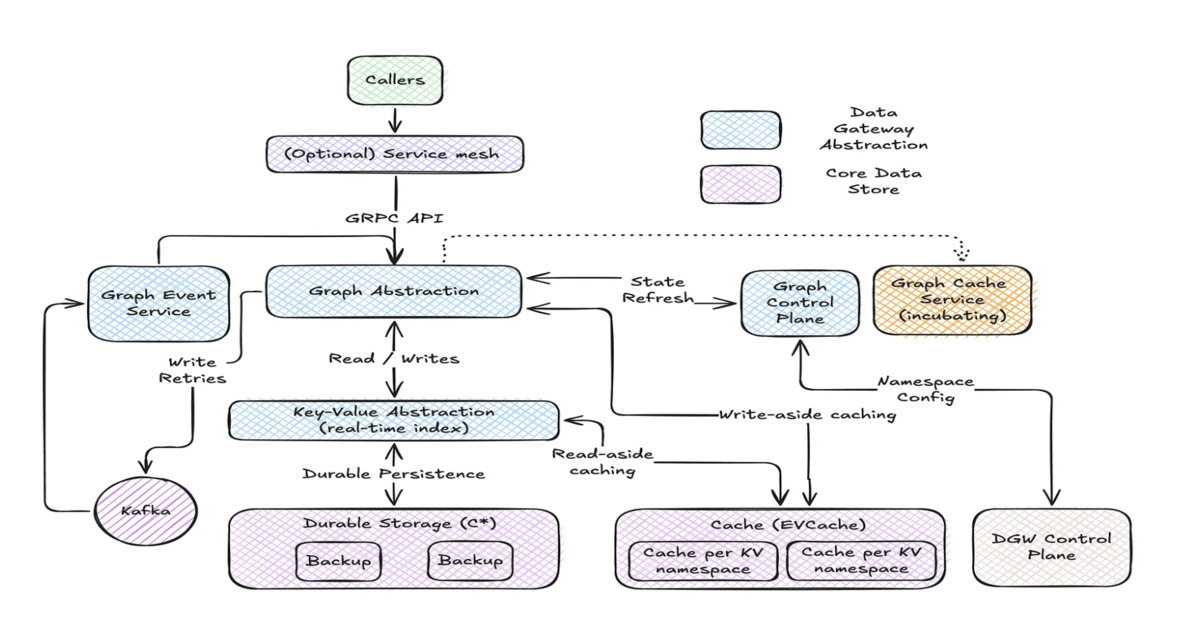
Netflix's 'Graph Abstraction' system represents a significant engineering feat, tackling the formidable challenge of managing 650TB of graph data with millisecond latency on a global scale. The key innovation lies in its pragmatic approach: rather than building a novel graph database from scratch, it leverages existing infrastructure (Key-Value, TimeSeries, and EVCache) and imposes strict constraints on traversal depth and starting nodes. This trade-off is crucial; it sacrifices some query flexibility, often found in traditional graph databases optimized for deep, complex traversals, to achieve predictable, high-throughput performance essential for operational workloads. The system's ability to separate edge connections from properties and its reliance on memory-loaded, strictly enforced schemas are critical for optimizing traversal planning and execution. The asynchronous replication across regions, while ensuring eventual consistency, is a well-understood pattern for balancing availability and latency in global distributed systems. This architecture is particularly relevant for companies dealing with massive, interconnected datasets where real-time operational insights are paramount, such as service topology monitoring, social networking, and content recommendation engines.
However, the inherent limitations of restricting traversal depth and requiring a defined starting node could be a concern for use cases that demand highly exploratory, complex graph queries. While the system is designed for specific operational needs, its applicability to more research-oriented or ad-hoc graph analysis might be limited without significant adaptation. The reliance on EVCache for low-latency access means that cache invalidation strategies and consistency guarantees are paramount. Furthermore, while the article mentions the use of gRPC, a deeper dive into the specifics of the API design and its extensibility would be beneficial for developers looking to integrate with the system. The success of this abstraction is contingent on the robustness and scalability of the underlying data infrastructure, which Netflix has evidently invested heavily in. The future expansion into live content, gaming, and advertising highlights the system's adaptability, but the complexity of these new domains will undoubtedly push its boundaries further. Overall, Graph Abstraction is a testament to pragmatic engineering, prioritizing performance and scalability for critical operational use cases by making deliberate design choices and trade-offs.
Key Points
- Netflix developed Graph Abstraction to manage 650TB of graph data with millisecond global query times.
- The system powers internal services like Netflix Gaming's social graphs and operational monitoring.
- Key innovations include separating edge connections from properties and global data replication.
- It achieves low latency by leveraging existing infrastructure (Key-Value, TimeSeries, EVCache) and imposing traversal depth limits.
- Schemas are memory-loaded and strictly enforced for optimized traversal planning and validation.
- Caching strategies (write-aside, read-aside) reduce amplification and maintain performance.
- A gRPC traversal API, inspired by Gremlin, allows for chained traversal steps and filtering.
- Global availability is achieved through asynchronous replication, balancing latency, availability, and consistency.
- Production performance delivers single-digit millisecond latency for single hops and under 50ms for two hops (90th percentile).
- The system is designed for operational workloads requiring predictable, high-throughput performance.
📖 Source: Inside Netflix’s Graph Abstraction: Handling 650TB of Graph Data in Milliseconds Globally
Related Articles
Comments (0)
No comments yet. Be the first to comment!