
Uber's Petabyte-Scale Data Replication Overhaul

Alps Wang
Mar 3, 2026 · 1 views
Scaling Data Replication to Petabytes
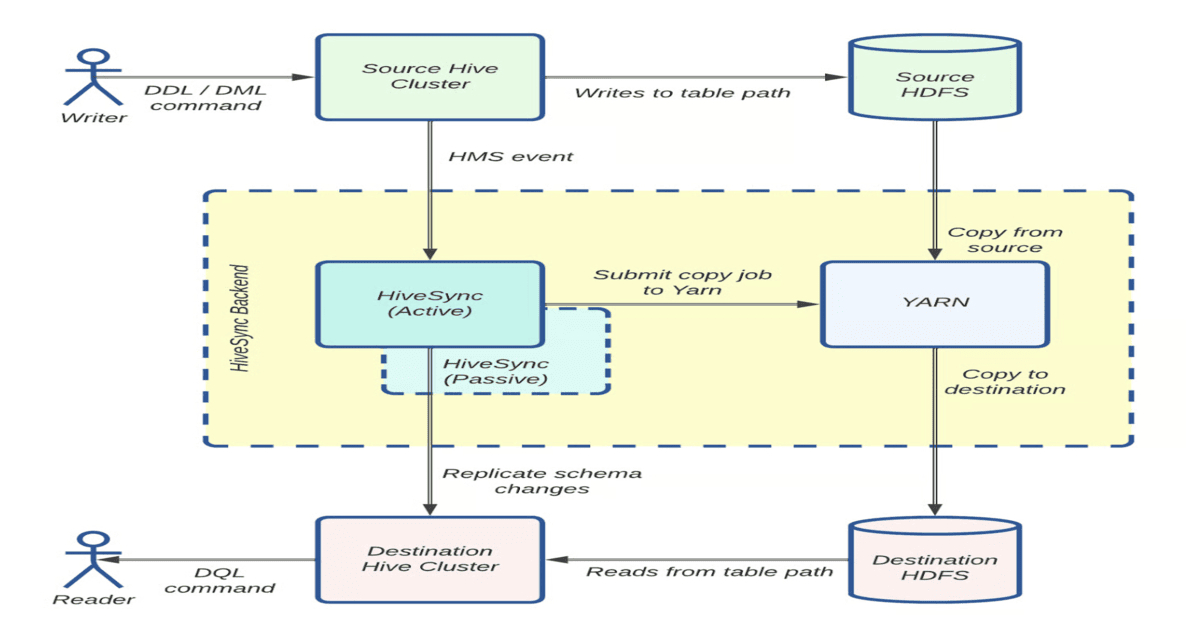
Uber's engineering team has successfully tackled the monumental challenge of replicating petabytes of data daily across a hybrid cloud environment, a feat crucial for modern, data-intensive operations. The core innovation lies in their deep optimization of the open-source Distcp framework, specifically by shifting resource-intensive tasks like listing and input splitting to the Application Master. This strategic move significantly reduces HDFS client contention and slashes job submission latency, demonstrating a profound understanding of distributed system bottlenecks. The parallelization of Copy Listing and Committer tasks further amplifies throughput, while the clever use of Hadoop's Uber job feature for small transfers dramatically improves YARN efficiency by eliminating unnecessary container launches. These architectural enhancements are not just incremental; they represent a fivefold increase in incremental replication capacity, enabling Uber to handle massive data migrations without incident.
The article highlights the importance of observability in managing such complex systems. By exposing granular metrics related to job submission, listing, and commit processes, along with resource utilization, engineers gain the visibility needed to preemptively identify and mitigate issues like out-of-memory errors or long-running tasks. The proactive use of circuit breakers, stress testing, and optimized configurations showcases a mature approach to operational resilience. Looking ahead, Uber's commitment to contributing these improvements back to the open-source community is commendable, fostering broader adoption and collective advancement in large-scale data management. The emphasis on even small improvements yielding significant gains at scale is a vital lesson for any organization operating at the cutting edge of data engineering.
However, while the article details impressive technical achievements, it could benefit from a more in-depth discussion on the trade-offs associated with these optimizations. For instance, the increased complexity introduced by moving tasks to the Application Master might have implications for maintainability or debugging. Furthermore, a deeper dive into the specific network configurations and challenges encountered during hybrid cloud replication, especially concerning latency and bandwidth management, would provide even greater practical value. While the mention of a dynamic bandwidth throttler is promising, more details on its implementation and effectiveness would be beneficial. The article also touches upon the active-passive data lake model, but the specific benefits and operational aspects of this model in conjunction with the replication strategy could be explored further. Despite these minor points, the article provides an excellent case study in overcoming extreme-scale data engineering challenges.
Key Points
- Uber's HiveSync team optimized Distcp for petabyte-scale data replication in a hybrid cloud environment.
- Key optimizations include moving resource-intensive tasks (listing, input splitting) to the Application Master, reducing HDFS contention and latency.
- Parallelizing Copy Listing and Committer tasks significantly improved throughput and reduced p99 latency.
- Hadoop's Uber job feature was used to improve YARN efficiency for small transfers by running mappers in the Application Master's JVM.
- Enhanced observability metrics were crucial for monitoring and preempting failures.
- Uber plans to contribute these optimizations as an open-source patch to the community.
📖 Source: Hybrid Cloud Data at Uber: How Engineers Solved Extreme-Scale Replication Challenges
Related Articles
Comments (0)
No comments yet. Be the first to comment!