
ClickHouse Cloud's Multi-Stage Query Execution Unlocked

Alps Wang
May 28, 2026 · 1 views
Unlocking PB-Scale Joins & Aggregations
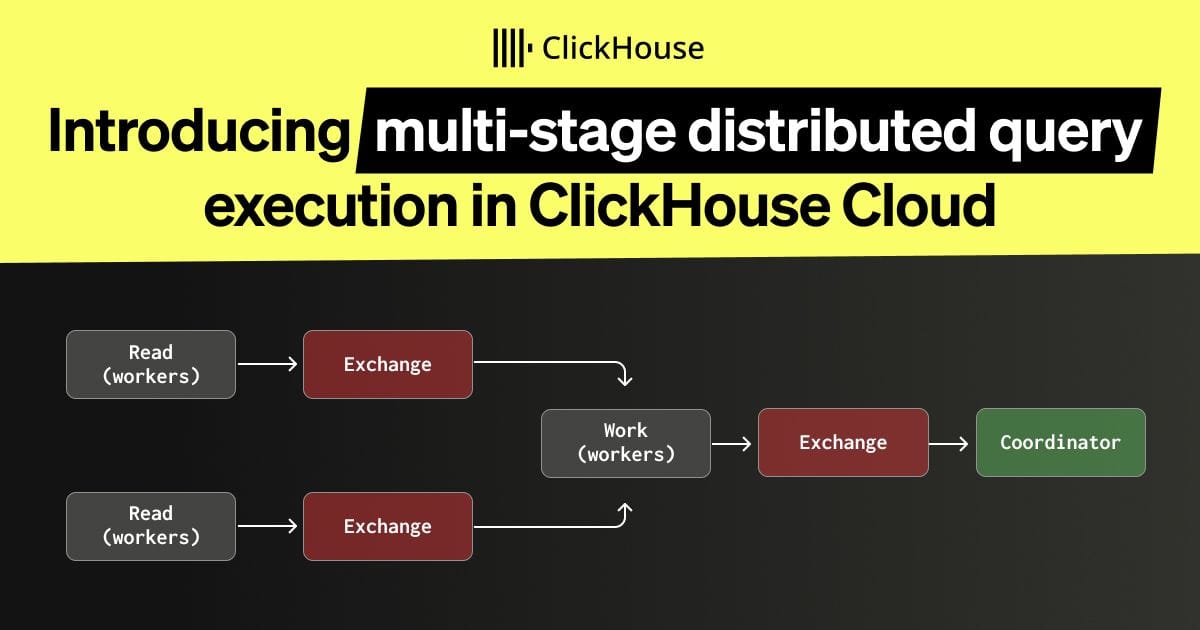
The introduction of multi-stage distributed query execution in ClickHouse Cloud represents a substantial leap forward in its ability to handle petabyte-scale analytical workloads, particularly complex joins and high-cardinality aggregations. The core innovation lies in enabling the dynamic repartitioning of intermediate data between execution stages, a capability that was previously a significant bottleneck. This allows for true horizontal scaling of individual queries, moving beyond the limitations of fixed sharding or simple replica parallelism. The article effectively details how this is achieved through exchange operators like ShuffleExchange and BroadcastExchange, fundamentally changing how queries are parallelized across a cluster. The performance gains, particularly the up to 3.4x speedup for join-heavy queries and near-linear aggregation scaling, are compelling evidence of its impact. The reliance on shared storage in ClickHouse Cloud is highlighted as a crucial enabler, making workers interchangeable and facilitating this dynamic repartitioning without data copying. This architecture is particularly beneficial for organizations dealing with massive datasets where traditional distributed database limitations hinder performance and scalability. The ability to avoid copying large right-side tables during joins and to prevent single-node bottlenecks in final aggregation stages directly addresses common pain points in big data analytics. The explanation of streaming exchange, with its pipelined data movement, further underscores the focus on interactive performance and efficiency.
However, while the benefits are clear, there are potential considerations. The increased complexity of query plans with multiple stages and exchange operators might introduce new challenges in query optimization and debugging for users less familiar with these advanced concepts. While the article provides a good overview, deeper dives into the nuances of exchange operator selection and potential performance tuning for specific workloads might be beneficial in future content. The article mentions persisted exchange for fault recovery and spilling, but further details on its performance implications and use cases compared to streaming exchange would be valuable. For users migrating from simpler architectures, understanding the operational overhead and the learning curve associated with multi-stage execution will be important. Despite these minor points, the overall impact of this feature is undeniably significant, positioning ClickHouse Cloud as a much more potent solution for the most demanding analytical scenarios.
Key Points
- Introduces multi-stage distributed query execution to ClickHouse Cloud.
- Enables dynamic repartitioning of intermediate data between query execution stages.
- Addresses key bottlenecks in large joins and high-cardinality aggregations.
- Achieves up to 3.4x speedups for join-heavy queries and near-linear aggregation scaling.
- Leverages exchange operators (ShuffleExchange, BroadcastExchange, GatherExchange) for data movement.
- Benefits from ClickHouse Cloud's shared storage architecture for interchangeable workers.
📖 Source: Introducing multi-stage distributed query execution in ClickHouse Cloud
Related Articles
Comments (0)
No comments yet. Be the first to comment!