
Uber's OpenSearch Boost: Pull-Based Ingestion

Alps Wang
Feb 10, 2026 · 1 views
Reimagining Real-Time Indexing
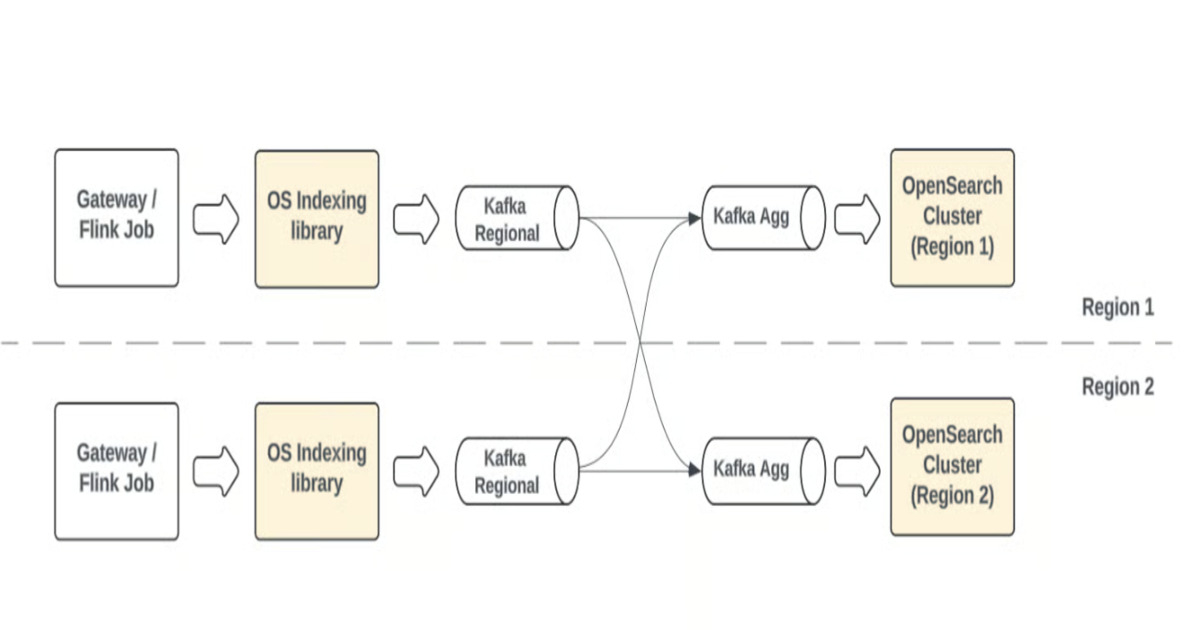
Uber's move to pull-based ingestion in OpenSearch represents a pragmatic solution to the challenges of scaling real-time search indexing. The shift addresses critical issues like backpressure handling and recovery, which are often pain points in push-based systems. The article highlights the benefits of using Kafka and Kinesis as durable stream buffers, allowing for controlled ingestion rates and efficient handling of bursty traffic. This architectural change directly impacts the reliability and stability of Uber's search infrastructure, crucial for applications like ride discovery and delivery selection, impacting a large user base. The focus on multi-region consistency and seamless failover is particularly noteworthy, reflecting the demands of a global platform. The detailed explanation of the pull-based pipeline, including components like stream consumers, blocking queues, and the ingestion engine, provides valuable technical insights for developers looking to adopt a similar approach.
Key Points
- Uber migrated from push-based to pull-based ingestion in OpenSearch to improve reliability and handle bursty traffic.
- Pull-based ingestion uses Kafka or Kinesis as durable streams, enabling backpressure handling and replay capabilities.
- The new architecture includes per-shard bounded queues, external versioning, and failure policies for improved operational control.
- Uber supports segment replication and all-active modes for different performance and cost trade-offs.
📖 Source: Uber Moves In-House Search Indexing to Pull-Based Ingestion in OpenSearch
Related Articles
Comments (0)
No comments yet. Be the first to comment!