
Target's LLM: Smarter Marketing Forecasts

Alps Wang
Jun 30, 2026 · 1 views
LLMs Powering Marketing Intelligence
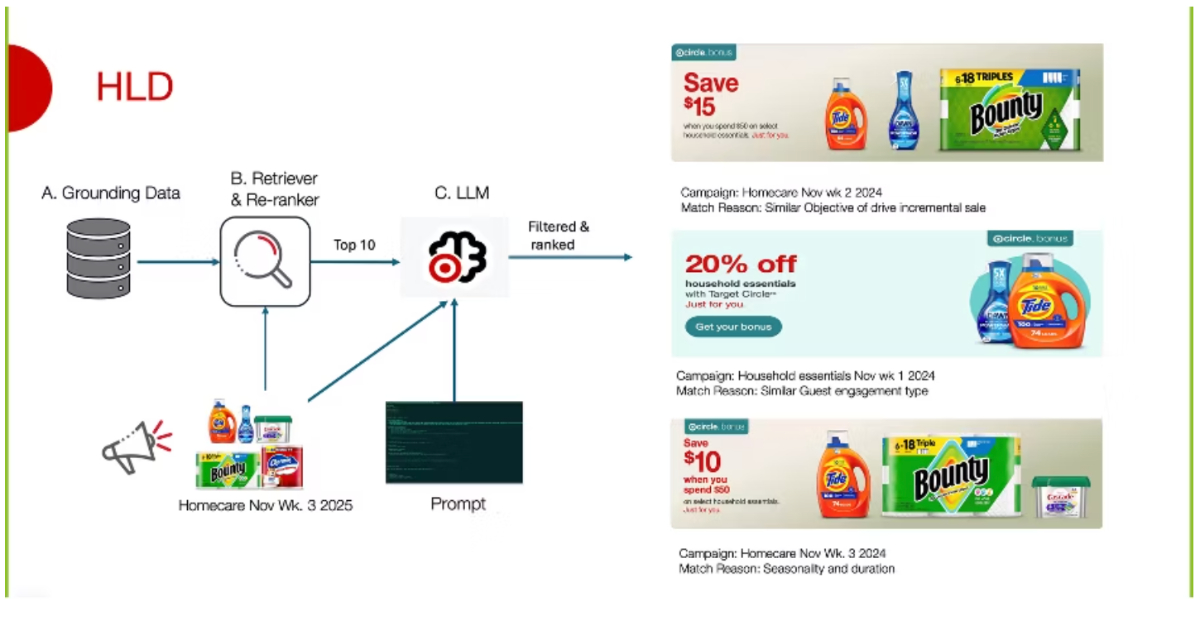
Target's implementation of an LLM-based system for semantic matching in marketing forecast pipelines represents a sophisticated evolution beyond traditional rule-based approaches. The core innovation lies in the retrieval-augmented generation (RAG) architecture, which effectively leverages embeddings to capture the semantic nuances of historical campaigns. By converting structured attributes into dense vector representations, Target can perform efficient similarity searches, a crucial step for surfacing relevant historical data. The subsequent LLM-based ranking and refinement stage is particularly noteworthy, as it moves beyond simple vector similarity to incorporate contextual signals and structured constraints, providing a more nuanced and interpretable output. The explicit separation of embedding generation, retrieval, and LLM ranking stages is a sound engineering practice, promoting modularity, independent tuning, and enhanced observability, which are critical for maintaining and evolving such complex systems.
The reported 75% coverage with the top-ranked recommendation and 100% with the top three highlight the system's effectiveness in reducing manual effort and improving forecasting consistency. This is a tangible benefit, especially as campaign diversity and complexity increase. The feedback loop, utilizing performance data from completed campaigns to refine embeddings, is a vital component for long-term system improvement and adaptability, allowing the AI to learn from its successes and failures. This approach directly addresses the operational overhead and generalization challenges faced by previous rule-driven systems, making it a compelling case study for other large organizations grappling with similar data-intensive forecasting problems.
However, a key limitation to consider is the inherent 'black box' nature of LLMs, even with explanations provided. While the system grounds recommendations in historical attributes, the precise decision-making process within the LLM for ranking and refinement might still be opaque to some degree, potentially requiring ongoing trust-building with marketing and analytics teams. Furthermore, the success of this system is heavily reliant on the quality and completeness of the historical campaign data used for embedding generation. Any biases or gaps in this historical data could propagate into the recommendations. The operational cost of maintaining and fine-tuning LLMs, alongside the infrastructure required for embedding storage and retrieval (likely involving vector databases), also represents a significant investment and ongoing challenge. The article mentions a feedback mechanism, but the specifics of how performance data is translated into embedding updates and the frequency of retraining are not detailed, which would be crucial for understanding the system's dynamic evolution.
Key Points
- Target has developed an LLM-based system for semantic matching in marketing forecast pipelines.
- The system uses a retrieval-augmented generation (RAG) architecture with embeddings and LLMs for ranking.
- Historical campaign data is converted into embeddings for efficient similarity search.
- An LLM ranks candidate historical campaigns, providing explanations for matches.
- The system achieved 100% coverage for evaluated campaigns when considering the top three recommendations.
- It replaces manual rule-driven logic, reducing operational overhead and improving generalization.
- A feedback mechanism uses performance data to refine embeddings and improve retrieval quality over time.
- The architecture is modular, separating embedding generation, retrieval, and LLM ranking for independent tuning and observability.
📖 Source: Inside Target’s LLM-Based System for Semantic Matching in Marketing Forecast Pipelines
Related Articles
Comments (0)
No comments yet. Be the first to comment!