
Netflix's MediaFM: Unlocking Content with Multimodal AI

Alps Wang
Feb 24, 2026 · 1 views
The Power of Fused Context
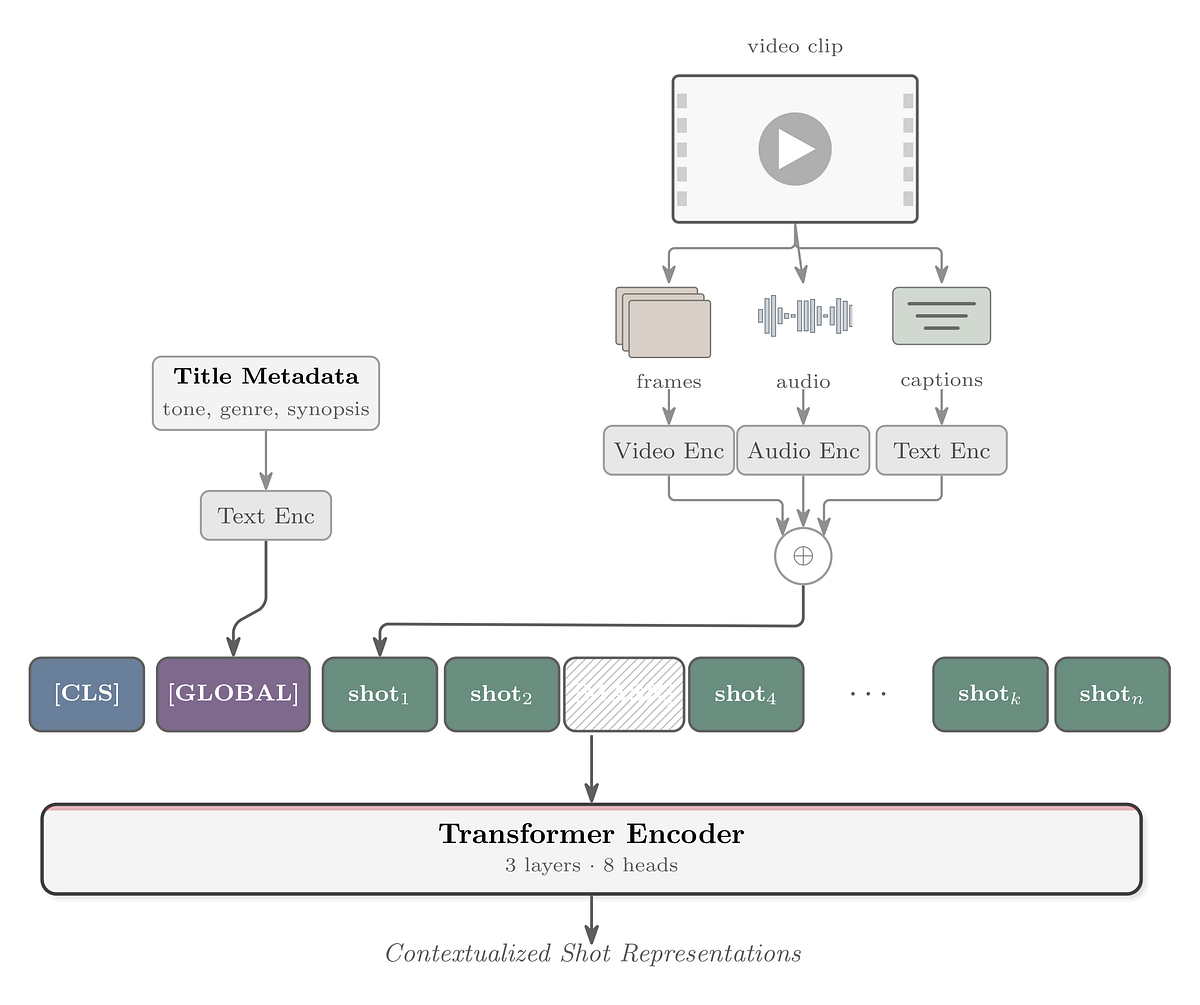
Netflix's unveiling of MediaFM represents a sophisticated advancement in multimodal AI for media understanding, directly addressing the complex challenge of deriving deep, machine-readable insights from vast content libraries. The core innovation lies in its tri-modal (audio, video, text) Transformer architecture, specifically designed to capture temporal relationships between shots. By integrating embeddings from models like SeqCLIP, wav2vec2, and OpenAI's text-embedding-3-large, MediaFM creates a rich, contextualized representation for each shot. The Masked Shot Modeling (MSM) objective, a self-supervised approach, is particularly noteworthy for its ability to train the model on Netflix's proprietary data without requiring extensive manual labeling, a critical factor for scalability. The evaluation using linear probes across diverse tasks such as ad relevancy, clip popularity, and tone classification, where MediaFM consistently outperforms baselines, underscores its practical value.
The strategic decision to focus on embeddings rather than generative outputs is a key technical detail that emphasizes modularity and reusability across Netflix's ecosystem. This approach allows for a cleaner abstraction layer, enabling seamless integration with existing workflows and easier incorporation of new modalities in the future. The emphasis on contextualization as a primary driver of improvement, as highlighted in the ablations study, is crucial. It suggests that understanding the narrative flow and inter-shot relationships is paramount for nuanced media comprehension, surpassing the mere aggregation of individual modalities. The exploration of future directions, including leveraging pretrained multimodal LLMs like Qwen3-Omni, indicates a forward-looking strategy for continuous model enhancement.
While the article effectively showcases MediaFM's strengths, potential limitations could include the computational resources required for training and inference at Netflix's scale, although this is inherent to such large-scale AI models. The reliance on specific pre-trained models for initial modality embeddings (SeqCLIP, wav2vec2, text-embedding-3-large) also means that improvements in those upstream models could directly impact MediaFM's performance. Furthermore, while the article mentions that outputs are used to inform decisions rather than end-to-end automation, the exact mechanisms and the degree of human oversight required for each application could be a point of interest for further discussion. The article also notes that some improvements are in various stages of deployment, implying that the full impact is yet to be realized across all intended applications.
Key Points
- MediaFM is Netflix's in-house, tri-modal (audio, video, text) AI foundation model for media understanding.
- It leverages a Transformer-based encoder to generate rich, contextual embeddings for individual shots by learning temporal relationships.
- Key innovation lies in fusing audio, video, and timed text modalities and incorporating title-level metadata for global context.
- Self-supervised Masked Shot Modeling (MSM) objective is used for training, enabling learning from Netflix's extensive catalog.
- MediaFM demonstrates superior performance over baselines on various tasks including ad relevancy, clip popularity ranking, tone classification, and clip retrieval.
- The model prioritizes embeddings for modularity and reusability across Netflix services.
- Contextualization of shot representations is identified as a primary driver of performance improvements.
📖 Source: MediaFM: The Multimodal AI Foundation for Media Understanding at Netflix
Related Articles
Comments (0)
No comments yet. Be the first to comment!