
Netflix's LLM Post-Training Framework: A Deep Dive

Alps Wang
Feb 13, 2026 · 1 views
Deconstructing Netflix's LLM Framework
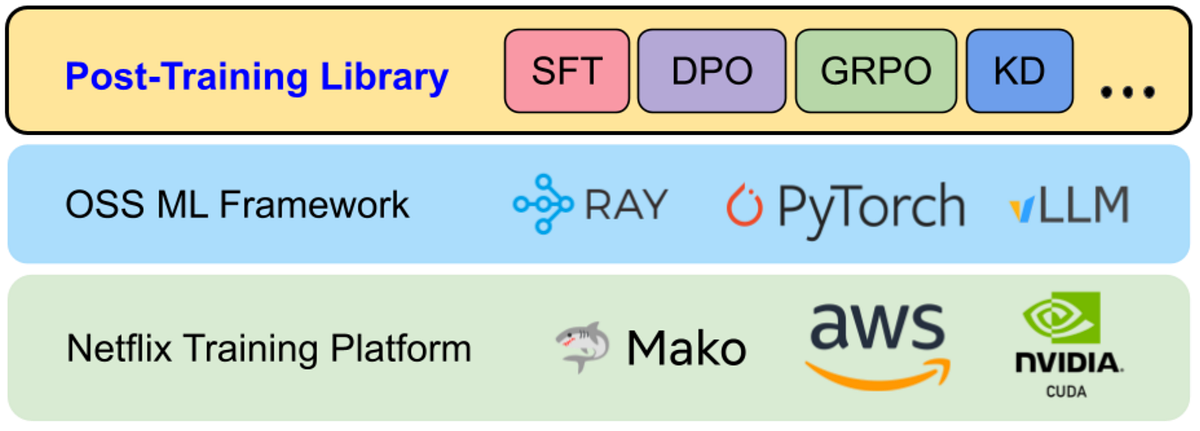
The Netflix Tech Blog post provides a detailed look into the engineering challenges of scaling LLM post-training within their ecosystem. The key insight is the development of a custom post-training framework that abstracts away the complexities of distributed systems, data pipelines, and model sharding, allowing model developers to focus on innovation. This is particularly noteworthy because it highlights the significant gap between the initial experimentation phase of LLMs and their deployment in a production environment at scale. The article emphasizes the importance of data quality, efficient model loading and sharding, and robust workflow management, especially in the context of on-policy reinforcement learning, where the training loop is more complex than in supervised fine-tuning. The framework's modular design, incorporating open-source components like PyTorch, Ray, and vLLM, while providing Netflix-specific optimizations, is a smart approach.
However, the article also has limitations. While it describes the benefits of the framework, it offers limited specifics on the performance gains (e.g., speedup factors, memory efficiency improvements) achieved through their optimizations. More granular details on the AI coding agent used for model conversion and its effectiveness would also be valuable. Additionally, the reliance on Hugging Face as the primary source of truth, though practical, might introduce a dependency on their ecosystem and potentially limit flexibility in the long run. The article doesn’t delve into the cost associated with maintaining such a framework, the number of developers supporting the system, or the impact on the speed of model iterations. The discussion of the hybrid SFT/RL architecture could benefit from a more thorough architectural diagram and a deeper exploration of the challenges of managing the distributed state in this hybrid approach. Finally, while the focus is on the engineering aspects, some discussion of the impact on model quality and the types of new member experiences enabled by the framework would be beneficial.
This article is most beneficial for AI engineers, ML researchers, and platform developers working on LLMs, especially those facing challenges scaling models for production use. It offers valuable lessons on building a flexible and extensible post-training framework that can accommodate different training paradigms and model architectures. It's a useful read for anyone looking to go beyond the initial experimentation phase with LLMs and build production-ready systems.
Key Points
- Netflix built a custom post-training framework to simplify LLM deployment at scale.
- The framework addresses challenges in data preparation, model sharding, and workflow orchestration.
- It supports various training paradigms, including SFT and RL, with a hybrid execution model.
- The framework leverages open-source tools but adds Netflix-specific optimizations.
- It prioritizes Hugging Face compatibility for model and tokenizer integration.
- AI coding agents automate model conversion, shortening the time-to-support for new architectures.
📖 Source: Scaling LLM Post-Training at Netflix
Related Articles
Comments (0)
No comments yet. Be the first to comment!