
Netflix's JDK Vector API: Turbocharging Recommendations

Alps Wang
Mar 3, 2026 · 1 views
From Bottleneck to Breakthrough
Netflix's deep dive into optimizing their serendipity scoring using the JDK Vector API is a masterclass in practical, systems-level engineering. The article meticulously details the journey from identifying a significant CPU hog (7.5% of total CPU) to a multi-stage optimization process. The key insight is that algorithmic improvements are insufficient without addressing fundamental implementation details like memory layout, allocation strategies, and efficient compute kernels. The evolution from naive loops to matrix multiplication, then to cache-friendly flat buffers with ThreadLocal reuse, and finally to the Vector API, showcases a robust engineering approach. The decision to prioritize pure Java solutions, avoiding JNI overhead and external dependencies, is particularly noteworthy for its focus on maintainability and portability. The success metric of a ~10% improvement in CPU/RPS and a reduction of the serendipity scoring's CPU footprint to ~1% is a strong testament to the effectiveness of this approach. The article effectively highlights the power of modern Java features like the Vector API, which allows developers to leverage SIMD instructions without the complexity of native code, making high-performance computing more accessible within the Java ecosystem. The detailed explanation of the fallback mechanism for environments where the Vector API is not enabled demonstrates a mature understanding of production deployment concerns, ensuring correctness and availability. This is an excellent case study for any team dealing with computationally intensive vector operations, especially in areas like AI/ML inference, recommendation systems, or scientific computing.
Key Points
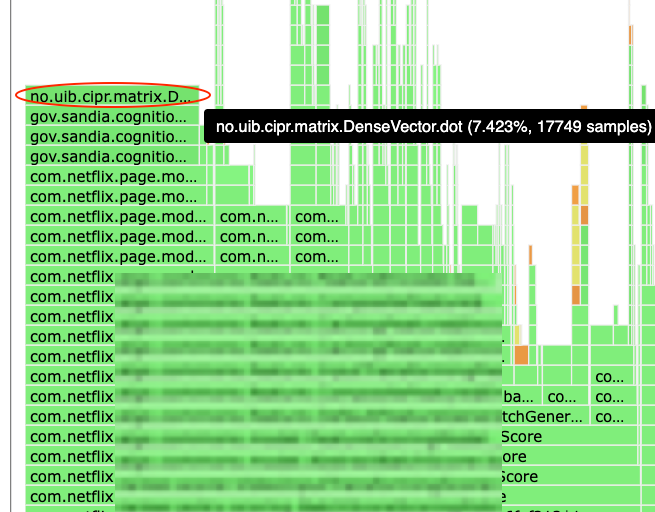
- Netflix's Ranker service identified serendipity scoring as a major CPU bottleneck (7.5% of total CPU).
- The optimization journey involved multiple steps: batching, re-architecting memory layout, and exploring various libraries.
- Key to success was shifting from O(M×N) dot products to matrix multiplication for batch processing.
- Initial batching implementation suffered from GC pressure and poor cache locality due to
double[][]layout and per-batch allocations. - Introduction of flat
double[]buffers andThreadLocal<BufferHolder>for reusable buffers significantly improved cache efficiency and reduced GC overhead. - BLAS libraries were explored but faced overheads from F2J, JNI transitions, and layout mismatches.
- The JDK Vector API provided a pure Java, portable solution for SIMD operations, mapping to native instructions (SSE/AVX2/AVX-512) without JNI.
- The final implementation uses a factory to select between Vector API (if available) and an optimized scalar fallback.
- Production results showed ~7% CPU drop, ~12% latency reduction, and ~10% improvement in CPU/RPS.
- The CPU footprint of serendipity scoring was reduced to ~1% of total CPU.
📖 Source: Optimizing Recommendation Systems with JDK’s Vector API
Related Articles
Comments (0)
No comments yet. Be the first to comment!