
Netflix Tackles Wide Partitions in Cassandra

Alps Wang
Jun 3, 2026 · 1 views
Dynamic Partitioning: A Cassandra Game-Changer
Netflix's approach to dynamically splitting wide partitions in Cassandra for time-series workloads is a sophisticated and pragmatic solution to a common scalability bottleneck. The two-pronged strategy, encompassing both table-level re-partitioning and ID-level dynamic splitting, demonstrates a deep understanding of the trade-offs involved. The Time Slice Re-Partitioning mechanism, leveraging Cassandra's introspection APIs and a background worker, provides an automated way to optimize partition strategies based on observed data, addressing the issues of unknown or evolving workloads. This is particularly valuable for large-scale deployments where manual tuning is unsustainable. The subsequent introduction of Dynamic Partitioning per ID is a significant advancement, directly tackling the problem of outlier TimeSeries IDs that skew performance, a scenario where table-level re-partitioning might be suboptimal or overly aggressive.
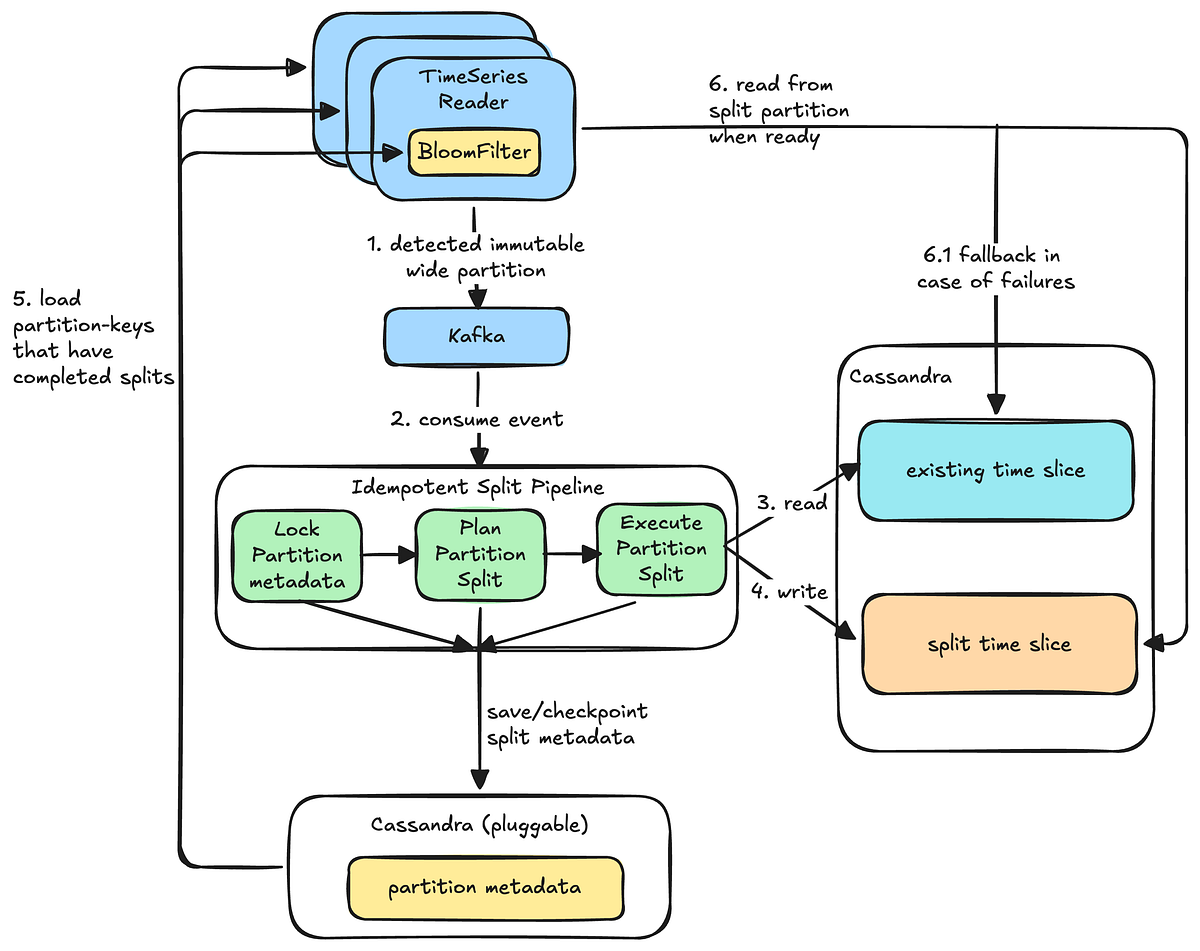
The technical implementation of the dynamic splitting pipeline, with its distinct detection, planning, splitting, and serving stages, is well-architected. The use of Kafka for detection events, the wide_row metadata table for state management and checkpointing, and Bloom filters for efficient read diversion showcases a robust design. The emphasis on immutability for the initial implementation of dynamic splitting simplifies complexity while still delivering value. The validation mechanisms, including checksums and the Data Bridge pipelines, are crucial for ensuring data integrity and building confidence in the system. The phased rollout strategy, especially the comparison phase in shadow mode, is a testament to their commitment to safe production deployment. This detailed approach to solving a complex problem in a high-throughput, low-latency environment is highly commendable and provides a valuable blueprint for other organizations facing similar challenges.
However, the reliance on read path detection for dynamic splitting means that some reads on wide partitions might experience sub-optimal performance for a short duration before the split is complete. While the article states this is typically seconds, in highly sensitive applications, even brief latency spikes could be problematic. The complexity of managing the wide_row metadata table and ensuring its availability and performance is also a potential concern. Furthermore, while the solution focuses on immutable partitions initially, the path to handling mutable partitions, as mentioned, will introduce significant complexities. The operational overhead of maintaining this dynamic splitting pipeline, while automated, will still require dedicated engineering effort. Despite these considerations, the overall innovation and impact of this solution are substantial, offering a path to significantly improve read latencies and reduce timeouts for time-series data in Cassandra at scale.
Key Points
- Wide partitions in Cassandra pose significant performance challenges for time-series workloads, leading to high tail latencies and timeouts.
- Netflix employs a two-pronged approach: 1) Time Slice Re-Partitioning for table-level optimization based on observed data and 2) Dynamic Partitioning per ID for outlier TimeSeries IDs.
- Time Slice Re-Partitioning uses Cassandra introspection APIs and a background worker to automatically adjust partition strategies for future time slices.
- Dynamic Partitioning per ID is an asynchronous pipeline that detects, plans, splits, and transparently serves data from wide partitions at the TimeSeries ID level.
- The dynamic partitioning pipeline leverages Kafka for detection, a
wide_rowmetadata table for state management, and Bloom filters for efficient read diversion. - Validation mechanisms like checksums and Data Bridge pipelines, along with phased rollouts and shadow mode comparisons, ensure data integrity and system confidence.
- The solution significantly reduces read latencies, bringing them down from seconds to milliseconds for previously problematic wide partitions.
📖 Source: Dynamically Splitting Wide Partitions in Cassandra for Time Series Workloads
Related Articles
Comments (0)
No comments yet. Be the first to comment!