
Google's Bayesian Teaching: Smarter LLM Belief Updates

Alps Wang
Mar 15, 2026 · 1 views
Probabilistic Reasoning for Smarter Agents
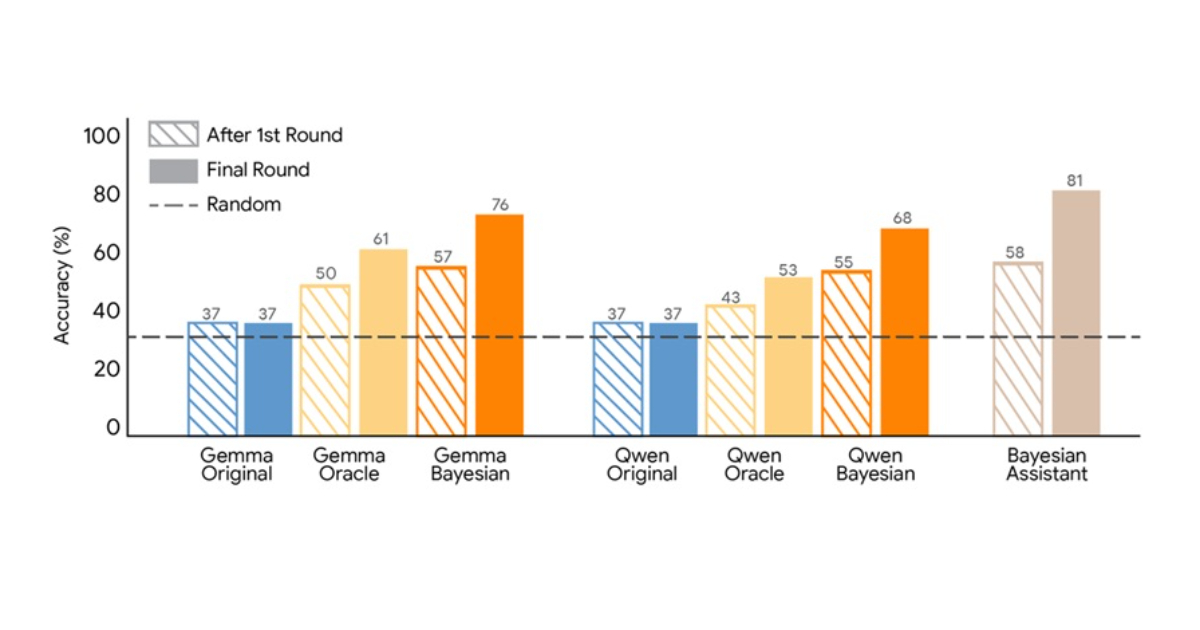
The core innovation presented by Google researchers lies in the 'Bayesian teaching' method, a novel approach to train Large Language Models (LLMs) to approximate Bayesian reasoning. Instead of traditional supervised fine-tuning on perfect answers, this method leverages the predictions of an optimal Bayesian system, even when those predictions are uncertain or initially incorrect. This allows LLMs to learn from imperfect, yet probabilistically sound, decision-making processes, thereby improving their ability to update beliefs and adapt in multi-step interactions. The simulated flight recommendation task effectively demonstrates the limitations of current LLMs in handling sequential feedback and highlights the superiority of Bayesian teaching in fostering more robust belief updates. This approach is particularly relevant for applications requiring dynamic inference, such as personalized recommendation systems, long-running AI agents, and any scenario where models must continuously refine their understanding based on evolving user input.
While the results are promising, a key limitation highlighted by the community, specifically Aidan Li, is the reliance on Supervised Fine-Tuning (SFT) rather than Reinforcement Learning (RL). RL is often considered more natural for optimizing sequential decision-making and probabilistic inference, given its ability to learn from rewards and penalties over time. The researchers' choice of SFT, while effective in this study, might not fully exploit the potential of learning probabilistic inference, and further exploration with RL could yield even more significant improvements. Additionally, the scalability of this 'Bayesian teaching' method to extremely large and complex real-world scenarios, beyond simulated environments, remains an open question. The computational cost of running an optimal Bayesian system to generate training data could be a bottleneck. Nonetheless, this research offers a valuable paradigm shift, moving LLM training beyond pattern matching towards a more principled approach to probabilistic reasoning, which is crucial for developing more reliable and adaptable AI systems.
Key Points
- Google researchers propose 'Bayesian teaching' to train LLMs to approximate Bayesian reasoning.
- The method involves training models to imitate the predictions of an optimal Bayesian system, rather than just correct answers.
- This approach aims to improve how LLMs update their beliefs with new information in multi-step interactions.
- Experiments show Bayesian teaching leads to better performance than traditional supervised fine-tuning in simulated scenarios.
- Community discussion highlights the potential impact on long-running agents and questions the choice of SFT over RL for probabilistic inference.
📖 Source: Google Researchers Propose Bayesian Teaching Method for Large Language Models
Related Articles
Comments (0)
No comments yet. Be the first to comment!