
DoorDash's LLM Chatbot Simulator: Testing at Scale

Alps Wang
Mar 14, 2026 · 1 views
Bridging the LLM Testing Chasm
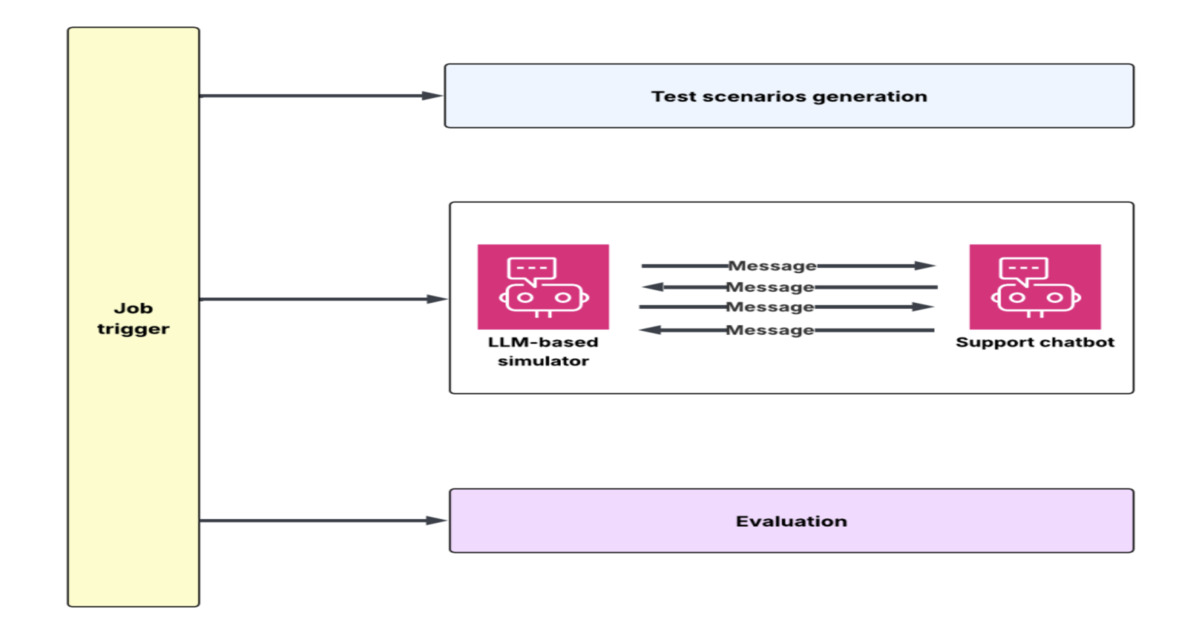
DoorDash's development of an LLM conversation simulator represents a crucial step forward in reliably deploying AI-powered customer support. The core innovation lies in its ability to mimic human customer interactions at scale, a stark contrast to the deterministic nature of traditional support systems. By using historical data to drive customer intents and behaviors, and mocking backend dependencies, they've created a realistic testing ground. This flywheel approach, encompassing simulation and automated evaluation, directly addresses the inherent unpredictability of LLMs, particularly concerning hallucinations and contextual errors. The reported 90% reduction in hallucination rates before deployment is a testament to the framework's effectiveness, highlighting its ability to accelerate experimentation cycles and improve AI agent reliability. The structured problem-to-production workflow, including LLM-as-judge evaluations, provides a robust methodology for iterative improvement.
While the described solution is highly impressive, a potential limitation might be the initial effort and expertise required to set up and maintain such a sophisticated simulation environment. The accuracy of the 'customer simulator' is heavily dependent on the quality and representativeness of the historical support transcripts. If these transcripts don't fully capture the breadth of customer issues or nuances in communication, the simulations might not perfectly reflect real-world scenarios. Furthermore, the 'LLM-as-judge' evaluation, while powerful, still relies on the underlying LLM's capabilities and potential biases, necessitating careful calibration against human judgment. The ongoing challenge of keeping the mocked APIs in sync with actual backend service changes also requires continuous attention. Despite these considerations, the value proposition for companies looking to implement or enhance LLM-driven customer support is immense, offering a clear path to de-risk deployments and accelerate innovation.
Key Points
- DoorDash has developed an LLM conversation simulator and evaluation flywheel for testing customer support chatbots at scale.
- The system uses an LLM to simulate customer conversations based on historical data, mimicking intents, flows, and behaviors.
- Mocked service APIs are used to reproduce realistic operational scenarios, including order lookups and refund workflows.
- An automated evaluation framework assesses outcomes against metrics like compliance, hallucination rates, tone, and task completion.
- This approach significantly speeds up experimentation cycles, reducing hallucination rates by approximately 90% before deployment.
- The framework addresses context window overload issues by structuring tool history into a case state layer.
- A structured problem-to-production workflow allows for iterative improvements based on identified failure modes.
📖 Source: DoorDash Builds LLM Conversation Simulator to Test Customer Support Chatbots at Scale
Related Articles
Comments (0)
No comments yet. Be the first to comment!