
DoorDash's DashCLIP: Multimodal AI for Smarter E-commerce Search

Alps Wang
Mar 17, 2026 · 1 views
Bridging Vision, Text, and Intent
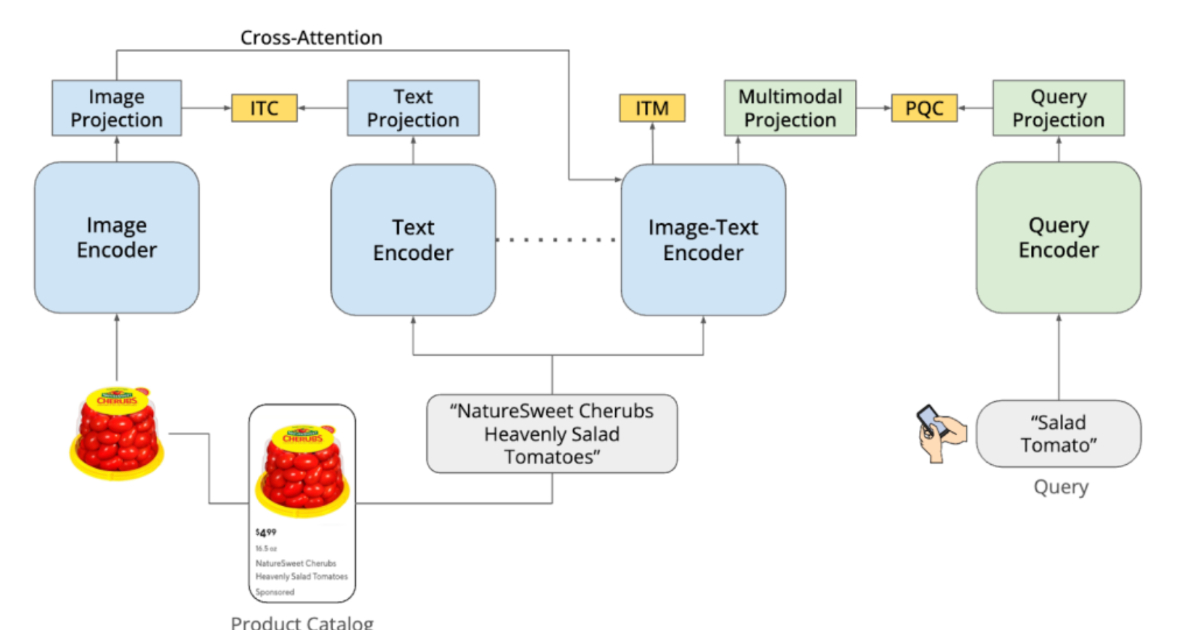
DoorDash's development of DashCLIP represents a sophisticated application of multimodal AI to tackle the inherent complexities of e-commerce search. By moving beyond traditional keyword and metadata-based systems, they are leveraging the power of semantic understanding across images, text, and user queries. The use of contrastive learning, inspired by CLIP, is a well-established approach, but its adaptation and scaling to 32 million labeled query-product pairs for a diverse marketplace is a considerable engineering feat. The two-stage training pipeline, starting with domain adaptation and then fine-tuning with a hybrid labeling strategy (human annotation + GPT expansion), is a practical and efficient method to build a robust dataset. This hybrid approach is particularly noteworthy as it mitigates biases inherent in relying solely on historical engagement data, a common pitfall in recommender systems.
The implications of DashCLIP extend beyond mere product discovery. Its ability to generate unified semantic embeddings opens doors for more relevant product ranking, targeted advertising, and even downstream tasks like category prediction. The reported success in offline and online A/B experiments, leading to production deployment for sponsored product recommendations, validates its effectiveness. For developers in the e-commerce and AI space, this offers a compelling blueprint for building more intelligent search and recommendation engines. The core concept of aligning multimodal data into a shared embedding space is a powerful paradigm. However, a potential limitation could be the computational cost and complexity associated with maintaining and serving these large-scale multimodal embeddings in real-time, especially as the catalog grows. Furthermore, while GPT-based labeling is efficient, ensuring the quality and accuracy of these expanded labels is crucial for the system's overall performance and to avoid introducing subtle biases.
Key Points
- DoorDash has developed DashCLIP, a multimodal ML system for semantic search.
- DashCLIP aligns product images, text descriptions, and user queries into a shared embedding space.
- It utilizes contrastive learning principles, similar to CLIP.
- The system uses separate encoders for images, text, and queries, generating vector embeddings.
- Training involved a two-stage pipeline: continual pretraining on product data and alignment with user queries using Query Catalog Contrastive (QCC) loss.
- A hybrid labeling approach, combining human annotation and GPT expansion, generated approximately 32 million labeled query-product pairs.
- This hybrid method aims to reduce bias compared to relying solely on historical engagement signals.
- DashCLIP embeddings have shown superior performance in ranking and retrieval tasks compared to baseline models.
- It has been successfully deployed for sponsored product recommendations and shows generalization to other tasks like category prediction.
📖 Source: DoorDash Builds DashCLIP to Align Images, Text, and Queries for Semantic Search Using 32M Labels
Related Articles
Comments (0)
No comments yet. Be the first to comment!