
Decathlon's Data Transformation: Polars Powers Faster, Cheaper Data Pipelines

Alps Wang
Dec 21, 2025 · 1 views
Polars: A Data Engineer's New Best Friend?
The key insight is the significant performance and cost gains achieved by Decathlon by switching from Apache Spark to Polars for smaller datasets. This is noteworthy because it highlights the importance of choosing the right tool for the job and the potential of Polars as a viable alternative to Spark in certain scenarios. The article also provides concrete numbers on speed improvements (reduced compute launch time) and cost savings (single-node Kubernetes pod vs. a Spark cluster), making it highly valuable. A limitation is that the article focuses on a specific use case (datasets under 50 GB) and doesn't explore the challenges of migrating larger, more complex Spark pipelines. The warnings about Kubernetes complexity and team adoption highlight important practical considerations. Those who are running Spark and dealing with smaller datasets, or evaluating alternatives to pandas will benefit most.
Key Points
- Using Polars on a single Kubernetes pod reduced compute launch time from 8 to 2 minutes and often completed jobs faster than a cold-started Spark cluster. However, it requires some Kubernetes management.
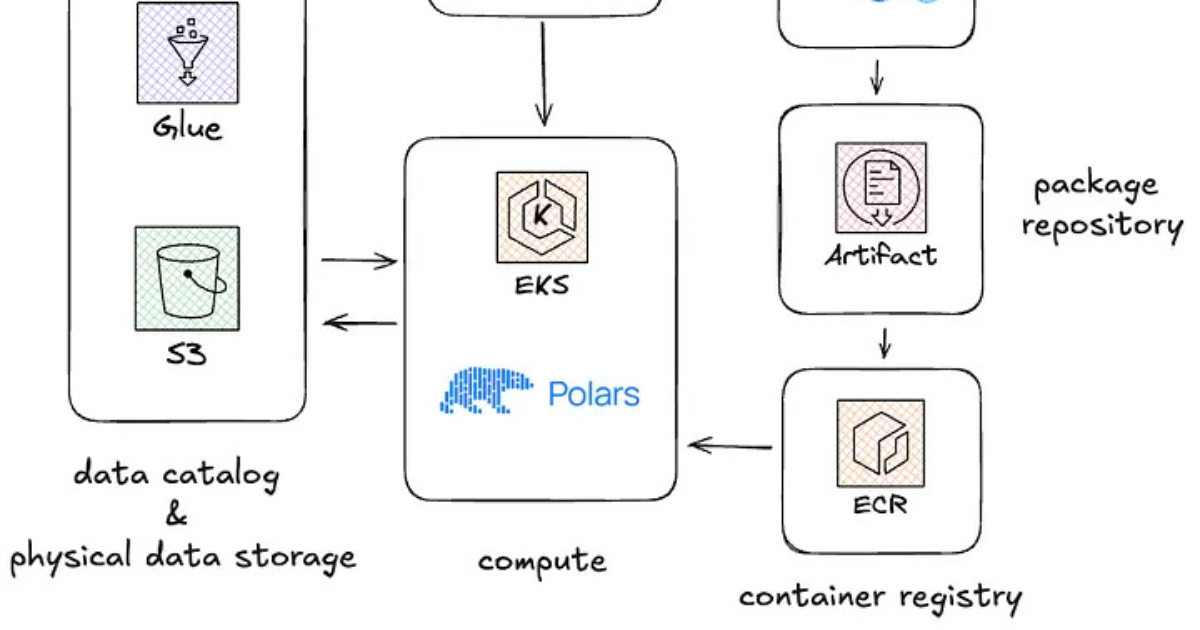
📖 Source: Decathlon Switches to Polars to Optimize Data Pipelines and Infrastructure Costs
Comments (0)
No comments yet. Be the first to comment!