
ClickHouse: Top-N Queries, Blazing Fast!

Alps Wang
Jan 20, 2026 · 1 views
Unpacking ClickHouse's Top-N Speed
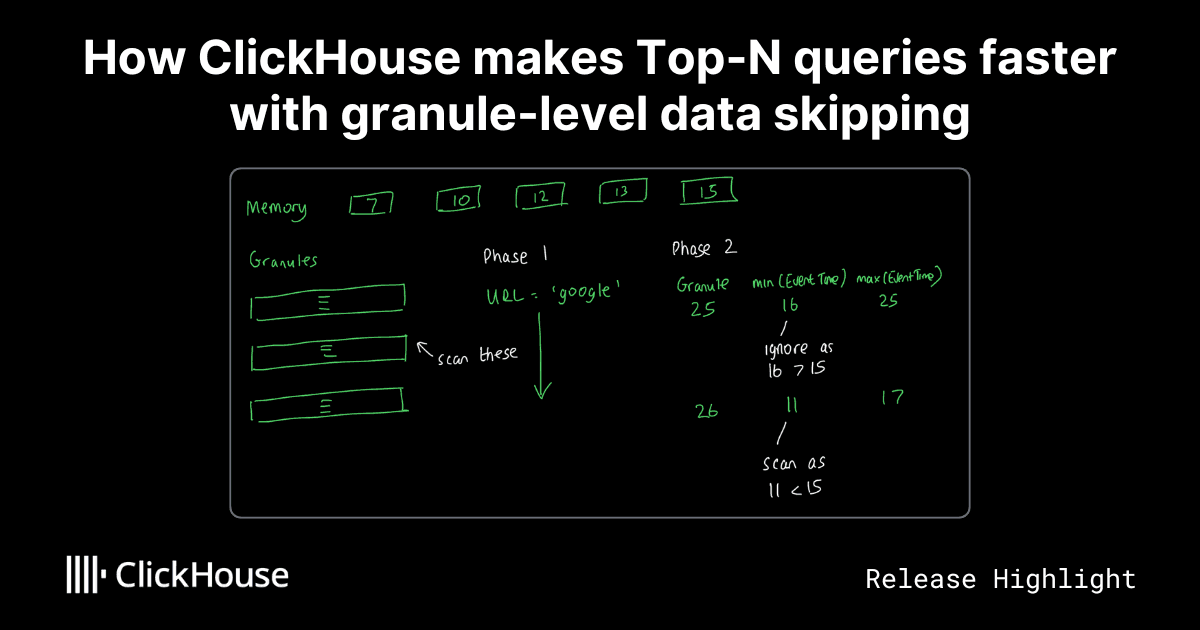
The key insight of the ClickHouse blog post is the effective use of data-skipping indexes at the granule level to significantly accelerate Top-N queries. This is achieved by comparing the current Top-N threshold with min/max metadata for each granule, thereby skipping entire granules if they cannot contribute to the result set. This approach is innovative because it moves the optimization upstream, before any data is read, which is crucial for large datasets and cold caches. The benchmarks provided demonstrate substantial performance gains, with query times reduced by a factor of 5-10x and data read reduced by 1-2 orders of magnitude. The dynamic Top-N filtering, incorporating predicates, is particularly noteworthy as it adapts to the evolving threshold during query execution.
One potential limitation is the reliance on the existence and effectiveness of minmax data skipping indexes. The performance gains are directly proportional to the quality of these indexes and the distribution of data within the granules. If the data is poorly distributed, or if the indexes are not optimized, the benefits will be diminished. Also, the blog post doesn't delve deeply into the overhead associated with maintaining these indexes, such as the cost of updates. A comprehensive analysis would include the index maintenance overhead and the impact on write performance. Furthermore, while the article highlights the advantages in object storage and disaggregated compute environments, it doesn't explicitly address the potential impact of network latency, which could become a bottleneck in such setups. Finally, the article primarily focuses on the technical aspects and could benefit from a clearer explanation of how users can easily implement and benefit from the new use_skip_indexes_for_top_k and use_top_k_dynamic_filtering settings, including best practices and potential configuration adjustments.
This optimization will greatly benefit users who frequently run Top-N queries, such as those involved in data analysis, monitoring, and reporting. Specifically, users dealing with large datasets and those using ClickHouse in cloud-based or object storage environments will experience the most significant performance improvements. The ability to skip data before it's read also reduces costs related to I/O and network bandwidth, which is a critical consideration for cost-conscious users. The article provides a compelling case for adopting ClickHouse for analytical workloads where Top-N queries are common.
Key Points
- ClickHouse optimizes Top-N queries by using min/max data skipping indexes to skip granules before reading any data.
- This optimization significantly reduces the amount of data read and speeds up query execution, especially on large tables and cold caches.
- Static Top-N filtering (no predicates) uses upfront min/max metadata.
- Dynamic Top-N filtering (with predicates) adapts the threshold during query execution.
- Benchmarks show 5-10x speedup and 10-100x less data read.
- This feature composes with existing ClickHouse Top-N optimizations (streaming, read-in-order, lazy reading).
📖 Source: How ClickHouse makes Top-N queries faster with granule-level data skipping
Related Articles
Comments (0)
No comments yet. Be the first to comment!