
AI Bots Overwhelm CDNs: New Cache Strategies Emerge

Alps Wang
Apr 9, 2026 · 1 views
AI Traffic's Cache Reckoning
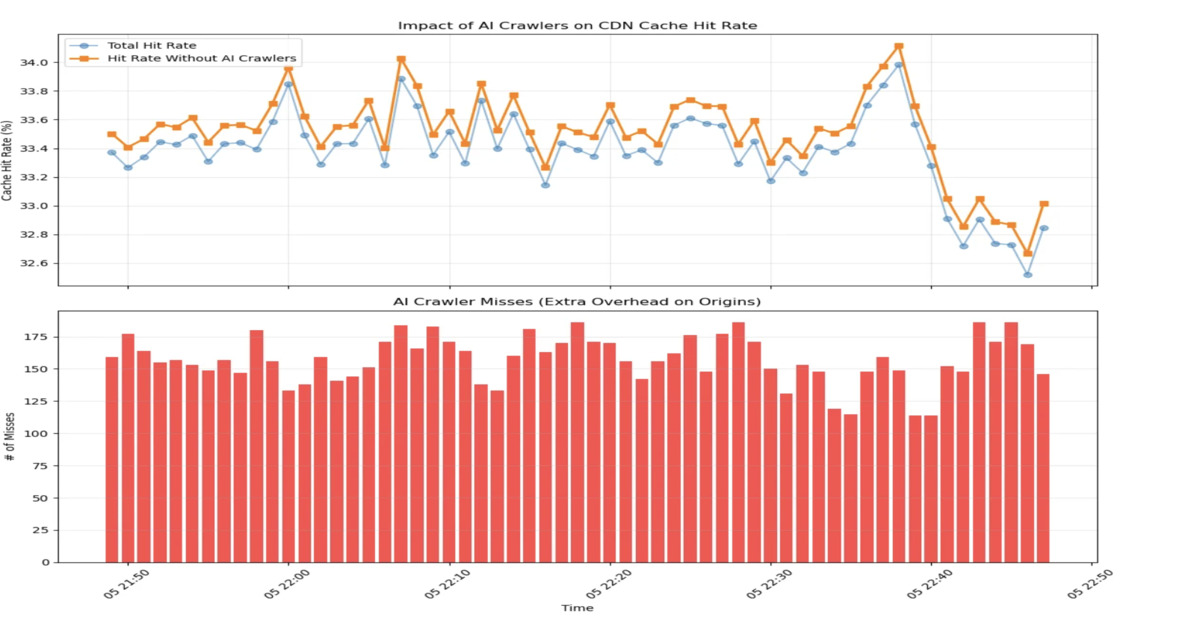
The article effectively highlights a critical and growing operational challenge: AI-driven crawler traffic is fundamentally altering access patterns in ways that traditional CDN caching mechanisms, optimized for human behavior, are ill-equipped to handle. The sheer volume and unique access patterns of AI bots, particularly in RAG loops, lead to significant cache churn and increased origin server load, directly impacting latency and resource utilization. Cloudflare and ETH Zurich's proposed solutions – segmenting traffic, exploring alternative eviction policies beyond LRU, and developing ML-driven adaptive strategies – are crucial steps towards addressing this. The observation that this issue extends beyond CDNs to databases, as noted by Aerospike's CFO, underscores the pervasive nature of this problem.
However, the article could benefit from deeper technical dives into the proposed ML-driven policies. What specific ML models are being considered? How will these models be trained and updated in real-time to adapt to the dynamic nature of AI traffic? Furthermore, while structured feeds and pay-per-crawl models are mentioned as complementary measures, their feasibility and potential impact on the broader AI ecosystem, including research and open-source development, warrant further discussion. The article also touches on the 'unpredictability' introduced by AI traffic, which is a core tenet of why traditional caching fails. Understanding how 'predictability' can be re-established or managed in an AI-driven world is key, and this might involve more nuanced approaches to content prioritization or even a redefinition of what constitutes 'cacheable' content in the age of AI.
Key Points
- AI bot traffic now exceeds 10 billion requests per week, significantly differing from human browsing patterns.
- AI crawlers exhibit high unique URL ratios and access diverse content, leading to cache churn and reduced cache hit rates.
- Traditional caching strategies like LRU are failing under AI load, increasing origin server strain and latency.
- Proposed solutions include traffic segmentation, exploring alternative cache eviction algorithms (LFU, FIFO), and ML-driven adaptive caching policies.
- Complementary measures like structured feeds and pay-per-crawl models can help manage AI access.
- The issue extends to databases, impacting predictable tail latency requirements.
📖 Source: Cloudflare and ETH Zurich Outline Approaches for AI-Driven Cache Optimization
Related Articles
Comments (0)
No comments yet. Be the first to comment!